
Akin to water, data is everywhere now, and akin to water, an overwhelming percentage of it is unfit for consumption. The bigger tragedy with data is that of the amounts that have been readied for consumption (read analytics); bad uses have dominated the good ones in public consciousness. Like Gresham’s law for money, there might just emerge an equivalent law for data: bad data drives out the good! Mark Antony might well have anticipated the current discourse on data if he had said—the evil that data does lives on after it, the good is oft interred with its bones.
But believe it or not, data has and will continue to do a lot of good. The good that data does if widely understood can be catalysed through good policy. Data also does a lot of bad and that can be used to drive good policy interventions to preclude abuses and override vested interests.
What has been breathtaking about data in recent times is the quantum of generation. Massive amounts of it gets produced, some voluntarily and most of it involuntary. The former because we choose to provide information about ourselves on social media, of our actions and sometimes even of our reactions to others’ posts. Involuntary data gets produced because devices (the ones we wear and the ones we get implanted!) are all eventually connected to the internet, recording our movements, our purchases, our conversations and perhaps even our thoughts. Besides, as the price of connectivity and devices plummets, there will hardly be any public space remaining that does not train cameras on us, all in the name of maintaining public safety. It’s as if someone is saying to you in vintage Bollywood style: Tu jahaan jahaan chalega, mera saaya saath hoga!
If the real world doesn’t tire of teaching us the perennial truth that life exists not in the edges at 0 or 1, but in the continuum in between, the reality with data is even more profoundly so. Between voluntary and involuntary data generation, there are an entire host of in-between data capturing practices that have emerged and that will evolve as rules and the associated case law becomes established. For example, online (and to an extent offline) purchases generate truckloads of data every second with regard to consumer preferences that are often used without consent. At the same time, admission to various portals requires disclosure of personal information without which access is barred or restricted, giving the user no choice but to comply. And in the vast majority of cases, users just check the boxes without reading the fine print, meaning that ‘informed consent’ is pretty much an oxymoron in the online universe. Emerging laws are, thus, mandating simpler and clearer communication of privacy policies potentially making online consent more meaningful.
As a result of massive technological breakthroughs, including wearable sensors and e-implants, data collection has exploded. According to The Economist, the world’s most valuable resource is no longer oil, but data, 90% of which has been created in the last two years, and the vast majority (more than 99%) of which is “dark and untouched.” Thus the opening comparison with water.
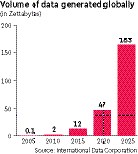
Additionally, data exhaust and digital trails left by this massive network of devices has become a cause of concern posing both risk to privacy and an opportunity for innovation. The International Data Corporation (IDC) estimates that 12 zettabytes of data were generated in 2015, of which only 0.05% was analysed. The IDC expects 47 zettabytes of data to be produced in 2020. Just to put things in perspective, 1 zettabyte is approximately equal to a thousand exabytes, a billion terabytes or a trillion gigabytes. Alternatively, a zettabyte is also expressed as 10(21) bytes. Storage that was prohibitively expensive only a few years ago, and warranted deleting files to make room for newer ones, will soon become redundant. It is estimated that 90% of the population will have unlimited and free data storage in the next three years.
Combine this data overload with artificial intelligence (AI) and the mix is as potent as Getafix’s ‘magic potion’. It can be ruinous if misused and gainful if not. Although AI has been around since 1956, its rise to become the hottest field in technology today can be linked to the ability of human beings to generate vast amounts of data, along with ever increasing capacity to store it. Data is the veritable feedstock for AI. What has got people excited about AI is that it can now be applied to so many different domains—health, education, e-commerce, psephology, elections, social media, businesses, public services, agriculture, manufacturing—the list is endless. Data along with AI is a deadly combination that makes the whole infinitely greater than the sum of its individual parts. If one watershed moment for AI was in 1997 when IBM’s Deep Blue beat Garry Kasparov, considered as the Greatest of All Time (GOAT) in classical chess, the second watershed may be unfolding right before our eyes.
The rise or fall of AI will depend on how the integrity of the underlying data is maintained. For example, data illegally obtained via Facebook, which allowed Cambridge Analytica (CA) to allegedly influence political behaviour through targeted ‘misinformation’, rightly stirred a hornets’ nest over how the data was obtained. CA was eventually forced to shut down, while Facebook lost billions in market value. Machine learning and AI-based content guidance systems are being created every minute in the fields of advertising, news and its converse ‘fake news’, among others, to target individuals based on their behaviour and psychographic profile. There are a plethora of examples of the damaging consequences of AI that involve abusing data for power, businesses and even vendetta. These things will happen and in ways that can harm individuals, destroy reputations, damage societies and impair our democracy.
Moreover, digital giants are likely to be the norm in this space due to the inherent and profound network effects. The clarion calls for breaking them in the manner that AT&T was broken in the 1990s to curb the monopolists’ innate abusive designs are going to be hard to replicate. But let that be another story for another time. The truth is that not all bad uses of data will be or can be nipped in the bud, but incidents such as CA help to create frameworks in which such incidents can be minimised, if not eliminated. Naturally, consumer groups are incensed and are calling for greater online protection and an uncompromised right to privacy as well as checks on misinformation and propaganda.
That the bad consequences of the AI-data combine have so far trumped the good does not imply the latter are small or inconsequential. In fact, over time, these could dwarf the bad as technologies diffuse and mature, and adapt to contexts. We know that AI will help enhance skills, create jobs that never existed earlier, help scientific discoveries, including for new drugs, spawn new businesses and business models, improve citizen services, make delivery quicker and more efficient, and radically change industries like healthcare and transport, making them better and perhaps even safer.
The possibilities are immense, but not credibly quantifiable right now. One estimate values these at $435 billion in 2025, but the forecast error is likely to be very large. Here, one point is worth emphasising. The large benefits will be contingent upon building trust among and between citizens, and the private and public sectors.
Trust has been a scarce commodity in the Indian ecosphere and within the AI-data combine its premium will rise exponentially. In data markets, trust is a vital property and its absence will make it hard to conquer the fear of surveillance capitalism that has gripped India (and the world). Innovation is unlikely to thrive in an atmosphere of doubt and suspicion. Thus, the public and private sectors need to build and nurture trust between and among themselves. And data can be the anchor around which this is created. Else, the perennial poetic lament ‘Hum ko unse wafa ki hai umeed, jo nahi jaante wafa kya hai’ will continue to hold back our progress.
(Richa Sekhani and Isha Suri, both at ICRIER, contributed to the article)