

– By Jayachandran Ramachandran
The last few quarters since the arrival of ChatGPT have created enormous opportunities for the development of various use cases using LLMs (Large Language Models). Many organizations are experimenting with the technology and have tasted some early success. Various research findings have reported that enterprise data is around 20% structured and 80% unstructured. While there has been significant progress in analysing structured data, most of the unstructured data is still untapped. Within the structured data world too, getting connected insights across data sources is still an evolving space. LLM technology has now opened the doors to explore the unexplored unstructured data. While organizations are coming to terms with connected insights from structured data, new technology empowers them to reimagine the world of connected insights from unstructured data. One step further, connected insights from both structured and unstructured data by amalgamating data science techniques and LLMs will be a game changer.
Reimagining enterprise search and content consumption with Retrieval Augmented Generation (RAG):
Large enterprises have diverse data and knowledge spread across various business functions. Various studies have revealed that employees spend around 20% of their time looking for the right information to make decisions. Enterprise search and content consumption is an interesting use case where LLMs offer great promise. Through prompt engineering, use cases are being developed which help provide content summary, topic extraction, conversational capability, etc. However, LLMS have limitations on the input context length that creates challenges for processing long-form content and context that spreads across multiple documents and multiple file formats such as pdf, doc, xls, ppt, mp3, mp4, etc. Apart from in-context learning, partial fine-tuning and full fine-tuning of LLMs are some of the options. But they are resource and cost intensive. In addition to that, there are not many data points available to substantiate such a model’s effectiveness. To overcome these challenges, RAG is proposed as a viable alternative. RAG provides contextual content using keywords and semantic search to instruction-tuned LLMs to provide apt narratives. RAG architecture has the following key components as depicted in the diagram.
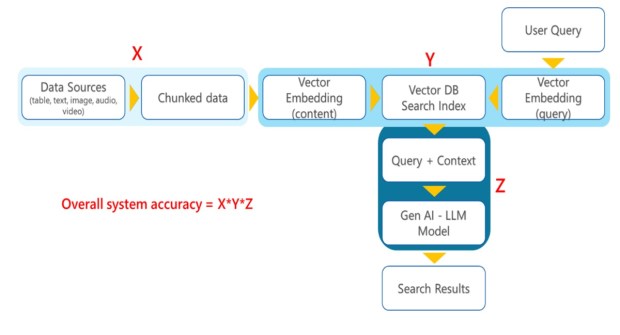
Data chunking: The content is chunked using various approaches such as standard fixed token length chunking, recursive chunking, context-aware chunking using sentence splitting, paragraph splitting, topic-based chunking, etc. Let’s assume the accuracy of this process is X.
Vectorization: Vector embedding of the chunks is stored in Vector DB and indexes are created for faster search. Vector embedding of the query is also done prior to search. Let’s assume the accuracy of this process is Y.
GenAI – LLMs: The query results that are most relevant and ranked high are passed to a large Language model for creating contextual narratives, topics, etc. Let’s assume the accuracy of this process Z.
The overall accuracy of a system which uses the RAG architecture is X*Y*Z.
When an organization uses out-of-box models for embeddings, Vector DB and LLM services from a third party, there is not much they can do to improve the accuracy of measures Y and Z. The only measure which is in their control is X, the accuracy of their organizational data.
Focus on data quality and robust data foundation:
While architectural frameworks like RAG offer great promise, they do not comprehensively cover the world of unstructured data. Documents come in different formats, including images, tables and external links embedded within it. Audio and video content add more complexity to the mix, since it requires speaker diarization, scene identification and scene narration. Processing such mixed-format data and creating contextual chunks is of paramount importance. The quality of contextual chunking, metadata tagging and its corresponding embedding will be the critical factor in determining the quality of the search results for each user query. In the GenAI technology landscape, where most components of the architecture will be common among participants, differentiation and competitive edge can be achieved by organizing the right data and orchestrating it in the right way. While technology will be a great leveler and enabler, quality data and robust data foundation will create a moat and differentiation in the GenAI world.
(Jayachandran Ramachandran is the Senior Vice President (AI Labs) at Course5 Intelligence.)
(Disclaimer: Views expressed are personal and do not reflect the official position or policy of Financial Express Online. Reproducing this content without permission is prohibited.)